PROTECT and SRP Researchers Investigate How to Make Data More FAIR
The projects funded by NIEHS’s Superfund Basic Research and Training Program (SRP) produce large amounts of data. Many of the projects cover multiple disciplines, spanning the fields of environmental science, health science, and more. Due to the transdisciplinary nature of much of the data collected, findings from SRP projects can ideally be used in other projects to answer different, yet related, questions. For data to be applicable to multiple projects and questions, data must be FAIR: findable, accessible, interoperable, and reusable.
In 2019, as part of efforts to improve the FAIR-ness of data, SRP facilitated collaborative projects to enhance data integration and interoperability. SRP centers collaborated with other centers that study similar questions with different data to develop data integration and management “Use Cases.” The teams worked closely with each other as well as data scientists to explore ways to integrate and share their data, and to examine present challenges in making data accessible. Nineteen Use Cases were formed, covering a wide range of questions.
Researchers from the PROTECT Center collaborated with researchers from the University of New Mexico and Dartmouth College SRPs for the Use Case on Data Harmonization Across SRP Pregnancy and Birth Cohorts. All three centers study the relationship between prenatal exposures and birth outcomes, but in different populations. The PROTECT Center studies the Puerto Rico Birth Cohort, The Dartmouth SRP Center studies the New Hampshire Birth Cohort, and the UNM SRP Center works with the Navajo Birth Cohort. The researchers focused on how they could integrate their biomonitoring, demographic, and environmental data from the three populations to increase the statistical power of their analyses and to explore a broader set of research questions.
The team set out to create a data infrastructure that could serve as a foundation for any study that looks at common toxicants and common birth and health outcomes across different populations. Finding opportunities for harmonization proved challenging, as data was collected and stored differently between the three centers and cohorts. To address this, the team evaluated each cohort’s data dictionaries to align common variables. With the expanded data dictionaries, the team was able was able to combine data across cohorts.
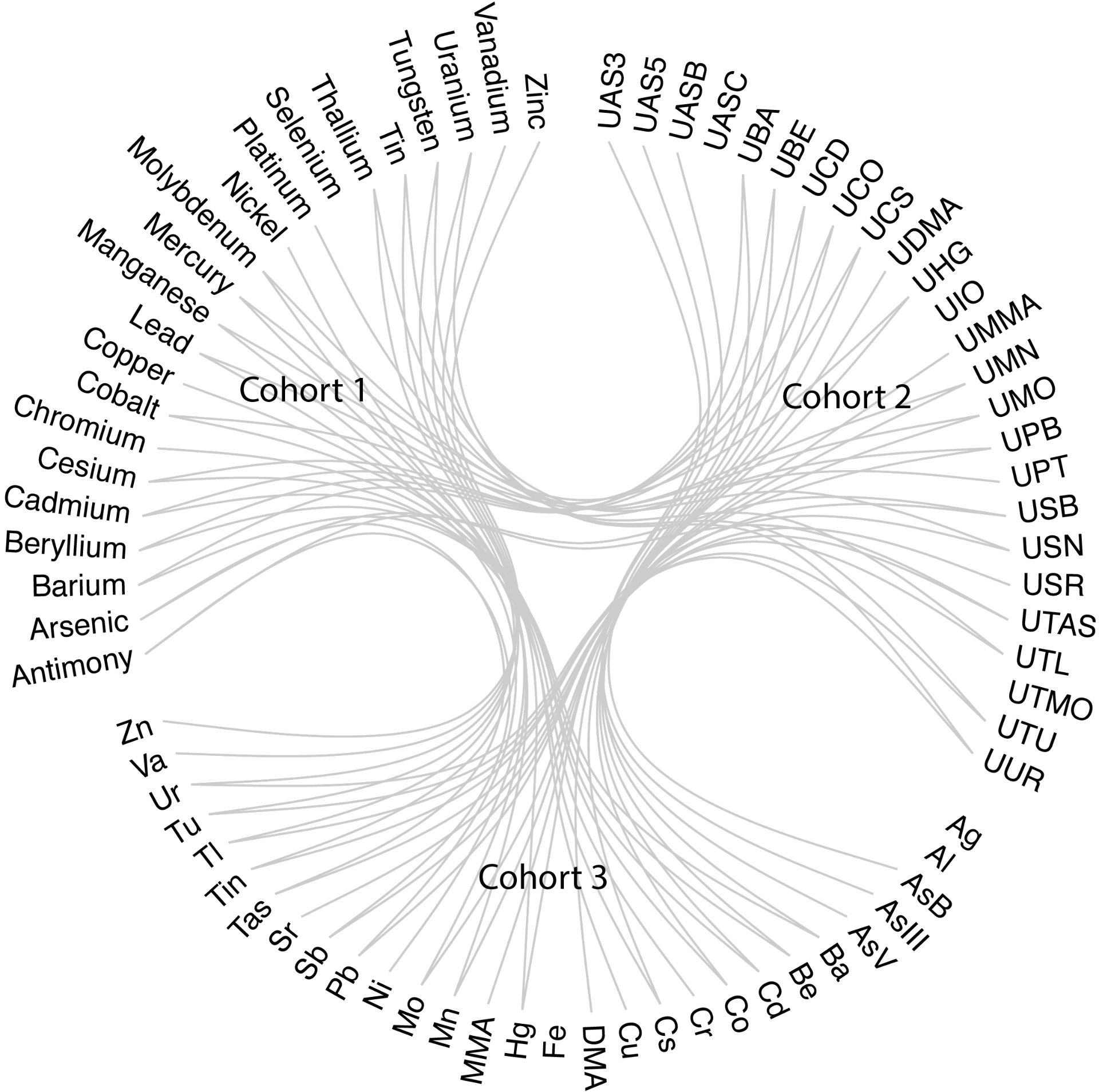
A visualization of the same data being named differently in different cohorts, a common challenge in data harmonization.
The team paid special attention to data privacy and security. Much of the data collected through these centers is personal health data from sensitive populations. To ensure the security of their data, the team developed their data analysis framework to be securely hosted by UNM and used several open-source tools to create a web-accessible processing platform. This new platform facilitates new scientific discoveries in a more cost-effective and accelerated manner as data and analysis are more accessible. The platform has already been used to perform statistical analyses and project hypotheses. The team’s work demonstrates that data sharing can be enhanced even when dealing with data from sensitive populations. The team hopes to share the tools and methodology used to make their framework with other researchers who deal with similar privacy challenges and sensitive data.
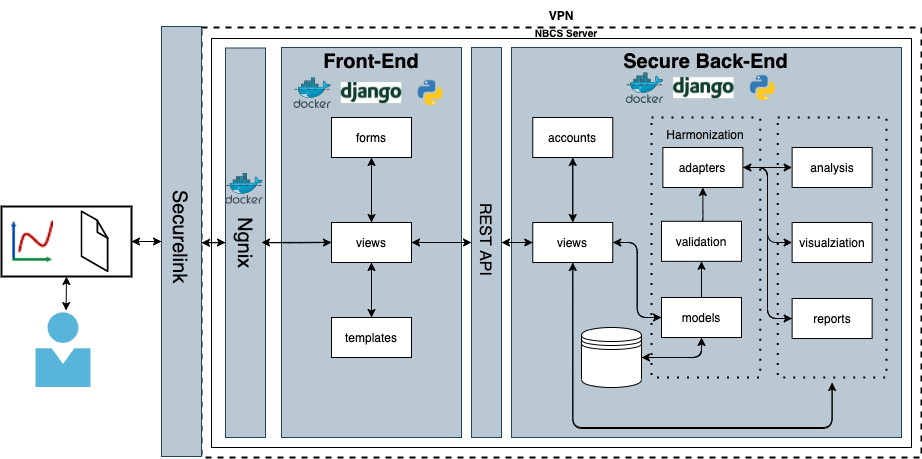
The architecture of the secure data analysis framework.
With more FAIR data, questions can be investigated in a more timely and cost-effective manner. PROTECT looks forward to working further with fellow SRP centers to develop tools and strategies that make data more accessible.
To read about all 19 Use Cases and the recommendations to make data more FAIR, you can read the full White Paper.